PPML Summer School: Python Overview¶
The purpose of this notebook is to help you setup the environment for python data analysis, so that you can start the course smoothly. After installing the python and extra packages, try running the codes in this notebook on your system.
Installing Python¶
For this course we will frequently use the following python "packages".
- numpy
- scipy
- pandas
- matplotlib
- sklearn
- jupyter notebook
While you can download and install each package from PyPI using PIP, I recommend you to install the Anaconda python distribution, which comes with some popular third party packages (e.g., numpy, scipy, and sklearn). Also, all the code examples and lectures will assume you have installed the Anaconda.
Installing Anaconda¶
Installing anaconda can be done with just a few clicks.
- Visit this page and read the instructions.
- Download the correct installer for your OS and architecture.
- Window/Linux/OS X
- 32bit VS 64bit
- Make sure that you download the Python 3.8 version.
- After the installation is done, test it by running the ipython.
You should see something like this:ipython
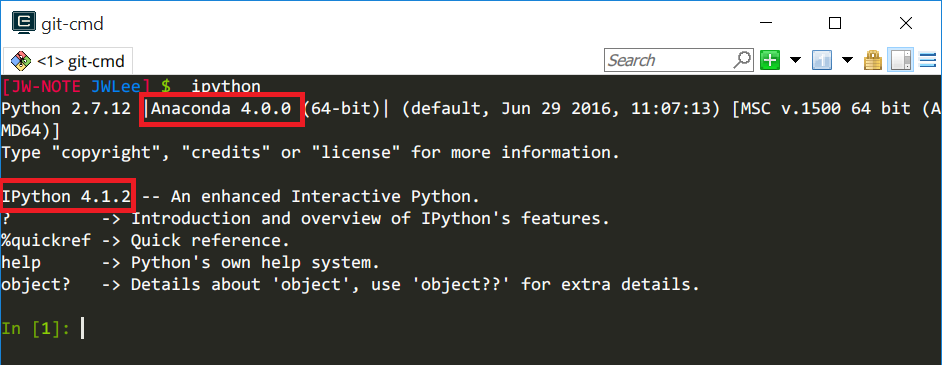
(Optional) If you already have installed Python or Anaconda¶
If you've been using Anaconda, then you just need to update the packages to their latest version.
conda update conda
conda update anacondaIf you have python installed on your system and don't want to install anaconda, you can try installing each package using the PIP, a python package installer. If you want to find more about pip, see this page. First, you need to update the pip to the latest version.
pip install --upgrade pip
Once it is done, try installing the following packages:
pip install numpy
pip install scipy
pip install matplotlib
pip installl sklearn
Jupyter Notebook¶
Notebook mode¶
Jupyter notebook has two different mode: command mode and edit mode.
- Edit mode: In edit mode, you can edit the content of a cell.
- Command mode: In command mode, you are not working with a cell but working with the entire document. See (here)[https://jupyter-notebook.readthedocs.io/en/stable/examples/Notebook/Notebook%20Basics.html] for details.
Keyboard shortcuts¶
When you are in command mode,
- Enter: enter into edit mode
- Shift + Enter: Run cell, select below
- Alt + Enter: Run cell, add a cell below
- Ctrl + Enter: Run cell
- a: add a cell above
- b: add a cell below
- m: change the current cell into a markdown cell
- y: change the current cell into a code cell
When you are in edit mode,
- Esc: Enter into command mode
- Shift + Enter: Run cell, select below
- Alt + Enter: Run cell, add a cell below
- Ctrl + Enter: Run cell
- Tab: auto-complete variable names
Now let's check the version of installed packages.
Q1. Report the versions of packages on your system (5 pts).¶
Run the following code on your system.

