 |
 |
 |
 |
 |
|||||||
Project 3: Scala - Predictive Wine Pricing with Decision Trees

Photo by: Linh Tinh
| Assignment Day | March 20, 2012 (Tuesday) |
| Due Date | March 29, 2012 (Thursday) (plan you time wisely, there may be an overlap, i.e., another assignment may be assigned on March 29). Note you have the solution in OCaML of this assignement, you job is to translate this Scala. |
Collaboration Policy - Read Carefully
You must work on this project individually, but you may discuss this assignment with other students in the class and ask and provide help in useful ways, preferable over our email list so we can all benefit from your great ideas. You may consult (but not copy) any outside resources you including books, papers, web sites and people.
If you use resources other than the class materials, indicate what you used along with your answer.
Objective
-
The main objective for this assignment is for you to familiarize yourself with production functional programming languages: OCaML and Scala.
- Another objective is to learn how to 'translate' an application from one language to another, just like you may do in real world programming.
Background
This project was originally assigned in this class in 2009, but at the time no source was available. This time around, however, you will have access to a student's source (used by permission) as a reference. This 'source' was working in 2009, but there is of-course no guarantee it works using the latest OCaML compiler. You may use this source as a reference or you may design your application from scratch.
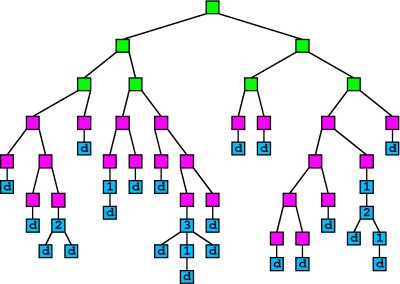
Overview: Decision Trees:
http://en.wikipedia.org/wiki/Decision_tree_learning
From wikipedia: "In data mining and machine learning, a decision tree is a predictive model; that is, a mapping from observations about an item to conclusions about its target value. In these tree structures, leaves represent classifications and branches represent conjunctions of features that lead to those classifications. The machine learning technique for inducing a decision tree from data is called decision tree learning."
Once a decision tree is created, one can use it to classify an object or observation as follows:
- Start at the root node of the tree.
- Follow one branch or the other depending on the result of a single question (or decision) at that node. Arrive at a new node.
- If the new node is a leaf, we are done, the classification value is stored in the leaf node. If not, go to #2 and continue.
The most popular use of decision trees (and the way we'll use them in this assignment) is automatic classification. As an example, given a set of measurements from an electrocardiogram (EKG), a decision tree could be used to automatically identify whether a person has a normal result or one of several types of arrhythmia. Decision trees are used in many other applications, including astronomy and biology.
Decision trees must first be trained (or built or learned) using a set of data that has been labeled by an expert. A labeled training example is a group of measurements (e.g., one person's EKG results) paired with a classification (e.g., "arrhythmia type A").
After training with labeled examples, the decision tree can be queried for automatic classification. As an example, in the EKG application mentioned above, we might record the assessments of recognized experts of EKGs from several hundred patients, then use their assessments as labels for training.

Photo by: Saquan Stimpson
Application for This Assignment:
Let's move to a concrete example that we will use in this assignment. A wine making company has decided that they want to use decision trees to predict the prices they can charge for their wine. Here's what they have done:
- They have measured 13 chemical properties of their wines.
- They have had experts taste each of their wines, and ranked them from 1 (best) to 3 (worst).
They want to use that data now to estimate the quality of new wines that they are creating now. So, they will measure the same 13 chemical properties to classify their new wines as 1, 2, or 3.
Example data for this application is available here:
Data: http://archive.ics.uci.edu/ml/datasets/Wine
How to Represent a Decision Tree
We will all use the same text-based representation of decision trees that our programs can read and write. This will be a comma-separated-value (.csv) file. Each line in the file will have the following information:
- Node number: starting at 1.
- Node type: 0 = leaf node, 1 = decision node.
- Decision feature num: This indicates which feature the decision is based on.
- Split value: If <= this value, follow the left branch, right branch otherwise
- Left branch node number
- Right branch node number
- Value (if leaf)
An example tree might look like this:
| Node | Type | Feature | Split | Left | Right | Leafval |
| 1 | 1 | 2 | 0.5 | 2 | 3 | 0 |
| 2 | 0 | 0 | 0.0 | 0 | 0 | 1 |
| 3 | 0 | 0 | 0.0 | 0 | 0 | 2 |
This is a very simple tree that returns a value of 1 if the second feature is less than or equal to 0.5, and a value of 2 otherwise.
Deliverables for the Assignment
You are to write, hand in, and demonstrate two programs: learnDT, and queryDT. I suggest you start with queryDT because it is simpler, and once you have it written you will understand decision trees better. queryDT works as follows from the command line:
queryDT decisiontree.csv testdata.csv > results.csv
queryDT takes a decision tree as input, along with test data, then it outputs a file of classifications. The test data is in the same format as the training data. The test data also includes the "correct" classification for each item (but your program should not "peak" at the answer). queryDT can "score" the quality of the decision tree by checking to see how well the automatic classifications work.
learnDT works as follows:
learnDT trainingdata.csv > decisiontree.csv
learnDT takes in training data from a comma separated text file, then outputs a decision tree as a comma separated text file. Each line in the training data file is one learning "tuple" or experience. Each line in the decision tree file represents a node or leaf in the tree.
You should also in the README file analyze how well your tree performs.
Algorithm for Learning a Decision Tree:
The classic algorithm is recursive, and it works something like this
DecisionTree learntree( trainingexamples )
if size(trainingexamples) == 1 // I'm a leaf
.....return leaf
else
.....featurenum = choose feature to split on
.....splitval = choose value to split on
.....leftexamples = splitleft( featurenum,splitval,trainingexamples )
.....rightexamples = splitright(featurenum,splitval,trainingexamples)
.....lefttree = learntree(leftexamples)
.....righttree = learntree(rightexamples)
.....result = combine(lefttree,righttree)
.....return(result)
Most versions of the algorithm differ mostly in how they choose which feature to split on. To get started, I recommend you just choose this randomly. Later, after you think about things, you may devise a way to choose the feature more intelligently.
Assignment Solution in OCamL.
project3/OCaML-Tree.zip (single tree)
project3/OCaML-RF.zip (forrest)
Submitting
|
| {nike:maria} submit cs4500_program3 cs4500 |
Summary of materials that you need to turn in:
|