Project 4: The Coordinator : A CPU Scheduler Simulator

The Coordinator
| Assignment Day | March 27, 2018 (Tuesday night) |
| Due Date | Before Class: April 12, 2018 (Th) [Demo in Class Required], not this intersects exam 2 - plan accordingly. |
Name the directory you submit P4 and submit code to csx730.
Overview
The primary focus of this project is to learn about scheduling policies and on their impact.
You will design and implement a general purpose simulator, call we call it the coordinator, of a simple operating system. You will start from scratch, no code will be provided.
To evaluate the utilty of your coordinator, and to get a notion of effective CPU scheudling policies, you will compare at least three fundamental scheduling policies: round robin, lottery scheduling and multi-level feedback scheduling.
Required Scheduling Policies:
1. Multi-Level Feedback Scheduling (agressive and non-aggressive)
2. Preemptive Shortest Job First.
Extensions Chose 1 for Bonus:
A. Lottery Scheduling.
B. Policy: Stride Scheduling (straight forward).
C. Policy: Linux: O(1) Scheduler
D. Policy: Linux : Completely Fair Scheduler (Linux, Red/Black Tree) (challenging).
E. Simulator Extension: Add another layer and simulate a multiprocessor.
Big Picture:

You will implement a system coordinator (we will sometime call the coordinator the simulator). The coordinator (or simulator) manages:
- jobs,
- devices, and
- schedulers
- -- all coordinated by a single loop of code (see image above).
A job is a 'customer' of services: it is a process that needs to use system resources during its execution.
A device represents a resource in the system. In this simulation, the devices available to a job are the CPU and the disk. There is also a clock device and a pseudo-device that interrupts whenever a new job arrives in the system.
A scheduler coordinates access to a device. It queues jobs that are waiting to use a device and will choose which job is the next to access that device.
The overall execution of the coordinator occurs like this: Jobs arrive at the job arrival device and are entered into the system. A job's lifetime consists of alternating periods of using the CPU (often called a burst) and performing I/O.
The Main Loop is responsible for moving jobs around the system. It sends them to a scheduler, takes the next job from a scheduler, and starts and stops jobs running on a device.
The Disk Scheduler and the CPU Scheduler decide which job should be the next to run on their respective devices. They also buffer jobs that are waiting to run but have not yet been given access. The clock device is used to enable preemption.
Code Structure:
Your project is to implement a simplified process management scheme using different scheduling techniques.
You need to keep track of various statistical data for each scheduling technique and job:
- total time each process was in each state,
- number of jobs run,
- total elapsed time,
- total elapsed time per job (throughput),
- total time each process is in a scheduling state: 1) waiting- ready ro run, 2) waiting for I/O, and 3) running on the CPU.
- longest and shortest time taken for any job in the system.
The coordinator works in a loop, a while loop, checking on events, specified below. At each interation a clock is incremented.
At least Seven things should be done in the coordinator loop during each cycle, the first six of pretty much map directly to the short term transitions of a process in a standard/classic operating system. See figure below (recall preemption occurs at the end of a time quantum or time slice).
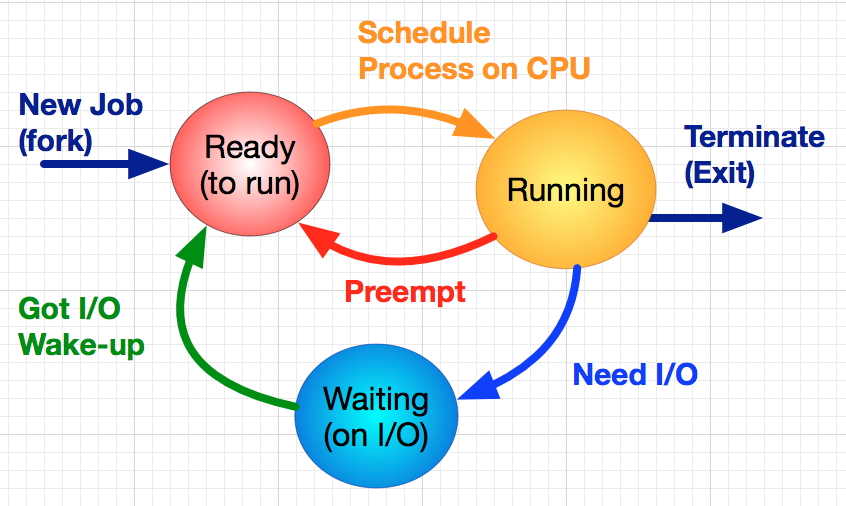
Your coordinator's main loop will resemble the following (with some variation depending on scheduling policy):
- if there are new jobs, put these jobs in the "ready to run" state
- if the job currently running on the CPU has used up its time-slice, then put it back in the appropriate queue (could be multiple queues) in the "ready to run" state.
- if the job currently running job requests I/O, then move it to "waiting (on I/O)" state.
- if a job is swapped out, then choose a new job to swap in.
- for all jobs waiting for I/O, check if their requests have been satisfied.
- if a job's I/O has completed move it to "ready to run" state
- keep track of statistics and update as appropriate.
Since our simulated jobs are doing no "real work", we have a little problem. If they are not actually executing code, they cannot request I/O. If they cannot request I/O, we can't transition from running to sleeping on I/O. And since there is no real I/O going on, I/O can never complete, so we cannot transition from sleeping on I/O to a ready to run.
This is a problem.
But we have a solution.
When a job is in the running state you
will have a function that "randomly" decides whether or not
the job has requested I/O. When a job is in the "waiting for I/O"
state, you will have a function that randomly decides whether or not I/O
has completed for that job. This I/O complete function is applied
to each of the jobs that are waiting for I/O in FCFS order. Pseudo
code for these functions are listed below.
#define CHANCE_OF_IO_REQUEST 10
#define CHANCE_OF_IO_COMPLETE 4int IO_request()
{if( os_rand() % CHANCE_OF_IO_REQUEST == 0 )}
return 1;
else
return 0;int IO_complete()
{if( os_rand() % CHANCE_OF_IO_COMPLETE == 0 )
return 1;
else
return 0;}
While writing your software use mrand() as a wrapper around stdlib's pseudo-random generator rand(), or srand(), or any other generator you like.
We will later provide a function called os_rand() to include randomness in determining I/O. This function os_rand() will not ``really'' return random numbers but will return specific numbers that have been pre-generated for you (that way everyone will get the same results). We will give more details on this function later.
Implemention Structure:
The coordinator should never be "idle" if there is an existing job. When jobs are completed, your scheduler will need to update any of its statistics and then process the next job, immediately. If a job is swapped back to "ready to run" state, it should be put on the queue assigned to its priority. For each job that the scheduler works on, that job's time remaining should decrease by one.Your project's main function could look something like this (in pseudo-code):
#include <stdlib.h>/* initialize clock */
clock=0;/* seeds the random number generator if you use rand(), or srand() */
os_srand(1); // wrapper - call srand if you use stdnlib rand()add new incoming jobs to the "ready to run" queue
/* (code here */
clock++;
while( there are jobs in the system ) // main coordinator loop{} /* End while if there are jobs in the system */
current_job = choose job to executewhile( 1 ) /* this loop is the main process management loop */
{
add new incoming jobs to the ready to run statewhile there are jobs waiting for I/O
/* check if this job's I/O is complete */
status = IO_complete()if status == 1
then put the job whose I/O has completed on the ready to run queueif this job has finished its work (if time remaining is 1)
then mark current_job as swapped out (job complete, exit)if you run a preemptive scheduler and there are now higher priority jobs on the "ready to run" state then :
mark current_job as swapped out (preempted)
/* check for I/O request from current_job */
if the job is not complete
then status = IO_request()if status == 1 /* need to do I/O */
then mark current_job as swapped out (sleeping on I/O)else if this job has been on the CPU for an entire time-slicethen mark the job as swapped out (end of time-slice) and
move it to the ready to run state
do bookkeeping and statisticsclock ++
if current_ job was swapped out then move the job to the appropriate queue and break from this loop
} /* End while main process management loop */
Note: "The choose job to execute" line will depend on your different
scheduling functions. (If the inner loop above is well thought out, it
should not have to change when your scheduling algorithm changes.) Also,
make sure you account for the case that no processes will run. In this
case, run an idle process (no statistics need to be generated for this
pseudo process).
Ties:
Break all "ties" according to PID number. This includes completed jobs on the IO Queue. You should *traverse* the IO Queue FIFO, but note if two jobs end up completing at the same time, since that would constitute a tie. Another example: if two processes with the same arrival time arrives at the same time, then the PID with the lowest ID should win:process PID 0 arrives at time 55then PID 0 should be inserted into priority queue 0 before pid 1.
process PID 1 arrives at time 55
Input and Output (I/O):
Your coordinator takes as input, standard input, which is assumed to be regular text in a specific for
This input specifies the
jobs that are to be scheduled and your coordinator will produce output statistics of the performance
of your coordinator.
{nike} thecoordinator < input_file.txt
Output format:
A sample output fromat would look like this (more on this later):
| Total time | Total time | Total time
Job# | in ready to run | in sleeping on | in system
| state | I/O state |
=========+=================+=================+===============
0 | 0 | 0 | 2
1 | 0 | 0 | 2
Total simulation time: 5
Total number of job: 2
Shortest job completion time: 2
Longest job completion time: 2
Average Completion: 2
Average Ready/Waiting: 0
Input format:
Jobs in this simulation will be simulated using a job data file that
contains 4 columns. The format is :
Process Id : Arrival time : Service time : Priority
NOTE: Priority needs to be provided, but is never used.
For example the data file, input_file.txt, is:
123:0:10:1
124:1:20:0
Describes a simulation that has two jobs.
The first has a pid of 123, an arrival time of 0 (when the simulation starts), it needs to do 10 clock ticks of work, and has an priority of 1 (which may not used by your program depending on your scheduler policy).
The second job has a pid of 124, arrives at clock tick 1, needs to do 20 clock ticks of work, and has an initial priority of 0 (again may or may not be used by your program).
The behavior of all the jobs your simulator will handle is described
in this data file. Associated with every job is a unique process
id (pid), the arrival time for the given job, a service time (how long
a job has until completion, i.e., how long the jobs "real work" will take),
and a priority rating.
Output Details:
The final output should be standard and follow the format given below:
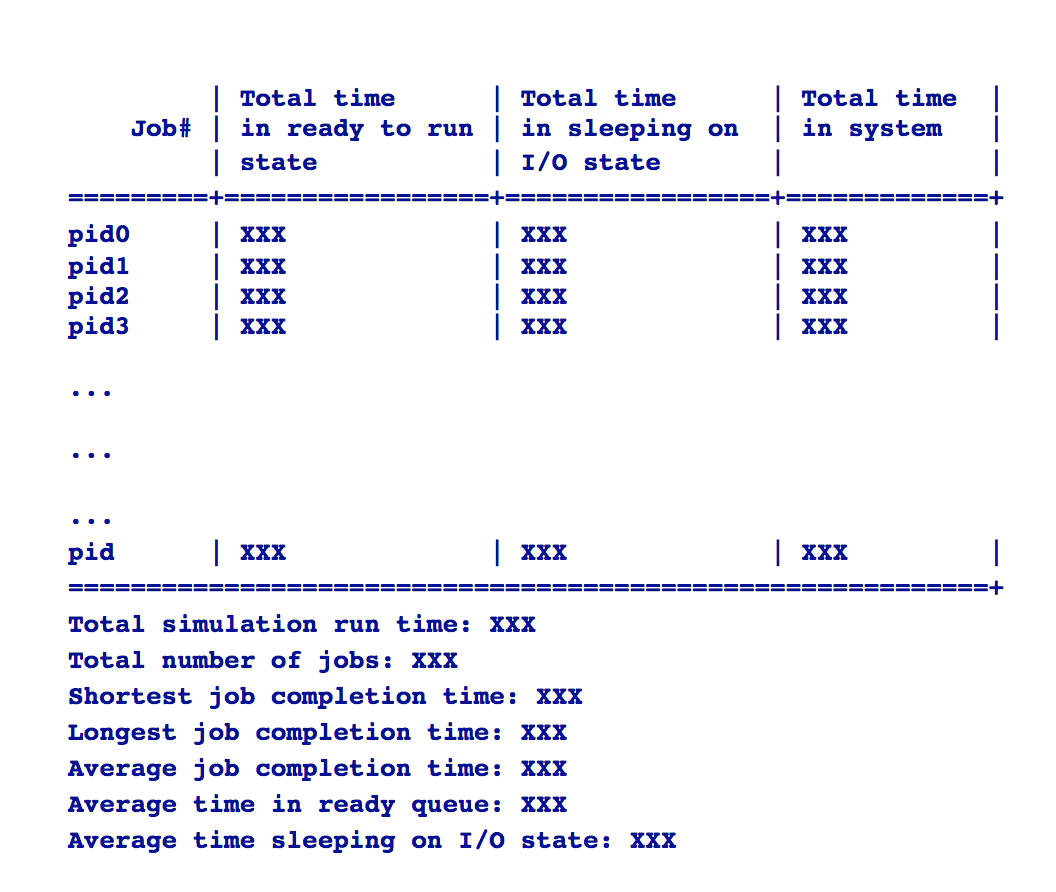
Verbose Output:
Your program is required to produce verbose output if given the "-v" flag on the command line. The verbose output will be written to stderr at every clock tick and consist of the following ONE line format:
# while the systems has jobs
<clock tick int>
:<pid id int>
:<remaining time for this job>
:<io_request_boolean>
:<io_requests_completed_list>
:<job state at end of loop>
| <pid id int> | the process id scheduled, an int. |
| <remaining time for this job> | remaining time of job |
| <io_request_boolean> | true or false; if there was an I/O request |
| <io requests> | list of pids requesting I/O, or "none" if none |
| <job state at end of loop> | "preempted", "still running", "sleeping", "idling", or * exited |
For example, the job file, input_file.txt, above (consisting of PID's 123 and 124) would
produce the following verbose output to stderr:
0:123:9:false:none:preempted
1:124:19:false:none:still running
2:124:18:false:none:still running
3:124:17:false:none:still running
4:124:16:true:none:sleeping
5:123:8:false:none:still running
6:123:7:false:0:preempted
7:124:15:true:none:sleeping
...
...
...
...
As another example, assume the following happens during clock tick 45:
job 123 is running, it does not request I/O, it has 15 clock ticks
until it exits, it has not used its entire time-slice, and the I/O completes
for jobs 234, 345 and 456. Then theverbose output for that cycle would be:
45:123:15:false:234,345,456:still running
If no I/O had completed it would be:
45:123:15:false:none:still running
If no process is running on the CPU the output would be:
13: *: x:false: 4 :idlingPID is denoted by a '*' since no process is running and the remaining time is denoted by an 'x'
If the process you ran completely terminated:, the output would be:
4: 5: 0:False:none :* exited
Command Line Options:
Your program needs to support a number of command line options.Your program must be able specify the algorithm that your are using on the command line. This will be done by the flags.
If none of the flags are set on the command line your simulator will run the non-aggressive version. An example command line illustrating the specification to run the aggressive version of your algorithm is listed below:"-A" is for the multi-level aggressive scheduling,
"-N" is for the multi-level non aggressive scheduling (default), or
"-S" is for preemptive SJF.
{nike} thecoordinator -AYou will also need to be able to set the various time slices for each of the seven priority queues on the command line. The defaults time slices are 1, 2, 4, 8, 16, 32, 64, 128 for each of the priority queues 0 to 7 respectively. You will set the time slices by the flags: -0, to -7. Where -0 denotes setting the time slice for priority queue with priority "0", and so on.
{nike} thecoordinator -0 4 -3 7Would set the time slices of priority queue 0 to 4 and priority queue 2 to 7. All other priority queues would use their default values.
You will also need to set the initial random seed on the command line, as well as the chance of I/O completion and I/O request. An example of a command line that sets these parameters is below:
{nike} thecoordinator -0 3 -s 1 -r 10 -c 4 -v -A < input.txt
Where-0 is the time slice of the highest priority queue, above it is set to 3 (the default of -0 is 1).
-1 is the time slice of the next highest priority queue
-2 , and so on... all the way to -7.
-s is seed value (where 1 is the default),
-r is I/O request chance (where 10 is the default)
-c is I/O complete chance (where 4 is the default), and
-v verbose output is on.-A, -N, and - flag allow you to specify the scheduling polices (see above).
Other Requirements:
- The project needs to be written in C.
- You may re-use code from your own projects that you have implemented previously (e.g., dequeue, enqueue procedures may be handy)
The simulation needs to be deterministic so our TA can grade it
without having to check everyone's output by hand.
In order for this to happen, we are in the process provided functions that reads random numbers and initializes the seed from a file.
These functions will be available in the project directory (shortly). You will need to implement your scheduler so that it can use both the random numbers from a file or the native functions srand(), and rand(), using wrappers, os_srand(), and os_rand().
Note in order to accomodate deterministic output, calls to the random function osrand() inside IO_request and IO_complete need to be called in the same order in everyone's implementation.
The order of calls are given in the above pseudo code, i.e., for each iteration of the inner loop you must first call the IO_complete, in a FIFO fashion, for all currently waiting jobs in the I/O queue, then call IO_request for the current job. Your implementation must follow this order.
Also everyone's implementation needs to seed using srand() via the wrapper os_rand(), before the main loop is started. To be deterministic everyone will use "1" as the seed to srand().
Scheduling Policies:
For Multi Level Feedback Scheduler you will implement one aggressive and one non-aggressive multi-level feedback scheduler, you will also impelement a pre-emptive.
The algorithm for each scheduler is described next.
Non-aggressive pre-emptive scheduler:
Aggressive pre-emptive scheduler:
- Jobs are scheduled according to priority, which ranges from 0 (highest priority) to 7 (lowest priority)
- When a job starts a burst (that is, when it becomes ready either because it has just started or because it has finished doing I/O), it is assigned priority 0 .
- The scheduler maintains a (FIFO) queue of jobs for each priority level. The scheduler will always run the first job of the highest priority level available (i.e. lowest-numbered non-empty queue). For example, if queues 0 and 1 are empty but queue 2 is not, the scheduler will run the first job in queue 2.
- When a job is run, it is assigned a slice, which is a number of quanta based on the priority of the job. A job at priority level 0 has a time slice length of 1 quantum, a job at level 1 has a time slice of 2 quanta, a job at level 2 has a time slice of 4 quanta, and so on. In general, a job with priority i has a time slice of 2i quanta.
- If a job with priority i uses up its time slice without blocking for I/O or terminating, the scheduler stops it, lowers its priority to i+1, and adds it at the tail of queue i+1, and selects a job as in rule (3). However if the job is already in the lowest priority queue, its priority is unchanged and it returns to the end of the same queue. While it is possible that the same job will be selected again--for example, if it is the only ready job--normally a different job will be given the opportunity to run.
- This policy is non-aggressive in the following sense: If a job becomes ready while another job is running, it is added to the tail of queue 0, but the running job is not stopped until it terminates, blocks for I/O, or uses up its time slice.
This version is a modified version of your first version. In this version jobs arriving at the CPU scheduler can preempt running jobs, and the priority of a job is ``remembered'' from one burst until the next. In more detail, rules (2) and (5) are modified as follows:
Preemptive Shortest Job First(2)' When a job becomes ready because it has finished doing I/O, it is given priority i-1, where i is the priority it had when it blocked for I/O. There is no level -1, so if a job finishes a burst at priority 0, it stays at priority 0. Newly created jobs are assigned priority 0. (5)' This policy is aggressively preemptive in the following sense: If a job becomes ready while another job is running, it is added to the tail of the appropriate queue as defined by rule (2'), the running job is stopped and has 1 subtracted from its priority (unless it is already at priority 0), it is added to the tail of the appropriate queue, and another job is selected to run as in rule (2).
In this strategy the ready queue will consist of one queue ordered according to the time that the scheduler 'thinks' the job needs on the CPU. You will need to calculate this "guess" using exponential averaging (p. 161 in textbook). The weight of the most current value is w and the default weight is 1/2.
Submission:
You must submit the following files (i.e., all the files necessary to
compile your project):
In addition to your coordinator you need to supply at least one input file (your_input_file.txt) and two corresponding output files (one for each algorithm). This input file is one that you have worked out by hand and have verified that you are getting the expected output (with your scheduler).
- thecoordinator.c
- all other files you need *.[ch]
- Makefile
- output.txt the (non-verbose) output of your simulator using the data file available in the project2 directory
- your_input_file.txt
- your_output_file_A.txt
- your_output_file_B.txt
- report.pdf
You need to submit all files using the submit file on nike.
Code Snippets
You can still start implementing/developing your code without these snippets, but you will need to provide code to eventually call these code via wrappers.
A P4 directory will have the code for various utility functions (mrand), that you need to c via wrappers os_rand(), and os_srand(). Please refer to the file: README-random.txt for information on how to use mrand() in your code.
[NOTE: in old definition of project we called the wrapper mrand ]
There is also a program that generates random numbers
We will also provide code demonstrates the use of the getopt() function that facilitates reading command line arguments in C and C++.
Please read the README.txt file on information of subdirectories.
http://cobweb.cs.uga.edu/~maria/classes/x730-Spring-2018/P4
Note: the output has a IO Completed column - this is optional, and you will not be penalized for not including the column.
Q/A
Question:
During each iteration of the internal loop, what exactly are we calculating for each process? Are we saying:
"This is what happened for the clock tick that just went past."?To start with, we load all jobs with arrival time of 0, then we increment the clock and step into the loop. We do a number of things. But, for each of those things, are we assuming that the process in question spent the clock tick from 0 to 1 in the state we're working with? This is especially important for tracking the timing of processes that change state on a given tick. For example, let's say I just incremented the clock to 12 and I come back around to the top of the loop. I check the 3 processes in I/O. Now, if one of them completes and goes to the Ready queue, should that clock tick (from 11 to 12) be counted toward time waiting in I/O or time waiting in Ready? My guess would be to count it toward I/O, because the process wasn't in the Ready queue when the clock was at 11. In essence, are we computing our various time values retroactively for the clock tick that just passed? (It determines how I'll do my bookkeeping...).
Answer:
Maybe this helps, think that clock denotes the end of the tick. So you assume that the job you select gets credit for the hole tick. Another way of looking at it is as you pointed out: this is what just happened at the clock tick.
- clock = 0
- add new incoming jobs to ready queue, the ready queue now includes jobs that starts at -- 0
- clock = 1
- enter main processing loop
- current_job selected from READY queue (of jobs starting at 0)
- enter inner processing loop -- the one that assumes a jobs is selected
- add NEW incoming jobs to ready queue, the ready queue now includes jobs that starts at -- 1
- should not be any IO_completes for the first iteration
- do some other stuff
- Suppose the process running requests I/O: io_wait_start = clock = 1
- clock = 2
- break out loop
- current_job selected from ready queue. Clock is 2, but the jobs in the ready queue starts at 1 or earlier since they were added into the ready queue BEFORE the clock was incremented.
- add new jobs to ready queue: NOW the ready queue includes job that starts at -- 2, these JOBS are available for selection in the NEXT iteration of the while loop
- do some stuff
- check for IO completion for all jobs that are waiting for I/O
assume that I/O completes at the end of the tick i.e at 2.
- add completed jobs to ready queue
- compute statistics of i/o job total_io_wait_time += clock - io_wait_start; So the first job the one that requested IO in step 10 waited for 1 tick
Question:
Would it be all right if I distinguished between preempted due to quantum expiration and preempted due to higher priority job(s) becoming available? It just so happens that I have a job coming off I/O on the same clock tick that the running job's quantum expires, and it looks like the -N algorithm is preempting the running job (unless you look closely), but I'd like the output to explicitly state why the job came off the CPU.
Answer:
That is fine. Even better.
Question:
Shouldn't the waiting queue be traversed in order of process entry? This makes a big difference in the deterministic outcome.
Answer:
Yes, the waiting queue should be traversed FIFO, like you did to ensure that the outcome is deterministic.
However, if they complete at the same time, then that would be a "tie", ties are broken by PID numbers. So if the PID number is lower than that PID has the priority.
Question:
In the description of the aggressive scheduler it says that a job should be preempted whenever a new job comes into the system. Is this the case only when the incoming job has a higher priority(closer to zero) than the running job. Or should preemption always happen
Answer:
Only when the incoming job has a higher priority (lower number).
Answer:
For people that are using tcsh or csh, to redirect the output of stderr and stout you will need to use '>&' For example:
scheduler >>& output.txtwill redirect standard output and error to the file output.txt
Question:
For the aggressive scheduler, if job1 is preempted, say job2 arrives, would job1 still run on that clock tick?
Answer:
As soon as a job is selected it is assumed it runs on the CPU for at least one tick. IO requests, preemption etc is assumed to happen at the very end of the clock tick.
Question:
I was looking at your verbose example and the suedocode and I have a question. It is impossible to have the first verbose output to show the clock time 0 and what happened during that clock cycle because you increase the clock to one before it enters the main loop. Do you want the clock to enter the main loop with 0 or 1?
Answer:
Show the jobs that you selected (if any) at clock tick 0 as the one that runs at clock 0. If you did not select a jobs at clock tick zero you should indicate that the CPU is idle.
Question:
The example for the verbose output (45:123:15:false:234,345,456:still running) shows 3 jobs completing IO on a single clock tick. shouldn't there be only 1 job IO completion per tick?
Answer:
Several jobs can complete on one clock tick.
Question:
Since jobs have to added to the ready queue based on their arrival time (which we determine by the clock), in the pseudo-code, the part that says "add new incoming jobs to the ready queue" should be inside of the while loop or else it is misleading. Could you take a look at it?
Answer:
There are two places where you should add new jobs to the ready queue.
One is outside the while loop and that adds incoming jobs with clock tick 0 or less. This is only done once.
The second place adds new incoming jobs for future iterations: clock-ticks 1 and later.
- clock = 0
- add new incoming jobs to ready queue, the READY queue now includes jobs that starts at -- 0
- clock = 1
- current_job selected from READY queue (of jobs starting at 0)
- add new incoming jobs to READY queue, the ready queue now includes jobs that starts at -- 1 NOW the ready queue includes job that starts at -- 1, these JOBS are available for selection in the NEXT iteration of the outer while loop
Question:
I assume that we're supposed to keep only 1 I/O queue, and that job priority really doesn't matter while it's in that queue. Jobs going into I/O always go to the tail of this queue, and we always check for I/O completion starting at the beginning of the queue. That way, job I/O completion is deterministic. Is this correct?
Answer:
Yes, please keep only 1 I/O queue (even if there may be multiple I/O devices. Yes again I/O completion should be checked FIFO (first in first out).
Question:
Do I *have* to use mrand()? I already wrote a function to load random.txt and convert it into a circular array of ints, and I've already written my own function to step through the array and get the next value each time I need a "random" number. Since I'm getting the values in the same order that they appear in the random.txt file, is it safe to assume that I don't need to replace the code I already wrote?
Answer:
No, in your case you do not have to use mrand. Yes if your function works as you say you should not replace your code.